CSS – przepis na piękno
Dariusz Półtorak 11-12-2010, 20:28
Spaghetti. Danie to ma na ogół estetyczny wygląd, jest smakowite i na pewno należy do moich ulubionych potraw. Niemniej jednak, gdy wszystkie składniki zostaną wymieszane i polane sosem, ciężko mi powiedzieć, z czego się dokładnie składa. Mogę powiedzieć, że jest tam makaron, mięso, sos, ale ciężko by mi było dokładnie zanalizować proporcje oraz przyprawy. Nie mówiąc już o poprawianiu tego dania. I tak właśnie jest z witrynami internetowymi. Są na ogół bardzo ładne, wiele z nich przypada nam do gustu, na wielu z nich jesteśmy w stanie zobaczyć ciekawe rozwiązania... ale ich skład i konsystencja są dla nas kompletnie nieczytelne.
Jeżeli teraz korzystacie z przeglądarki Firefox, to czytając ten artykuł, naciśnijcie skrót CTRL + U. Ukaże się Wam dokument, który otrzymała Wasza przeglądarka, gdy kliknęliście w link do tego artykułu. Tekst z dziwnymi znaczkami, który tam widać, to nic innego, jak opis strony, którą aktualnie oglądacie. Wyszczególnione są tam takie elementy, jak: nagłówek, menu strony, lista artykułów, tekst, który czytacie, reklamy itp.
Pytanie brzmi „jak ten spory kawałek tekstu zamienił się w kolorową stronę internetową?”. Odpowiedź jest prosta. Gdy przeglądarka otrzymała tekst, który widzicie w źródle strony, zanalizowała instrukcje tam zawarte i na koniec pokazała całość w oknie.
Strona internetowa zasadniczo składa się z 4 części:
Dzisiaj zajmiemy się językiem CSS, a dokładnie tym, jak i dlaczego należy go używać.

Jak już w skrócie napisałem, CSS to język służący do opisywania elementów strony WWW. Żeby dokładnie zobrazować, na czym to polega, rzućcie okiem na ilustrację 2. Jest na niej zdjęcie, które pokazuje nasz serwis informacyjny w przeglądarce bez obsługi CSS.
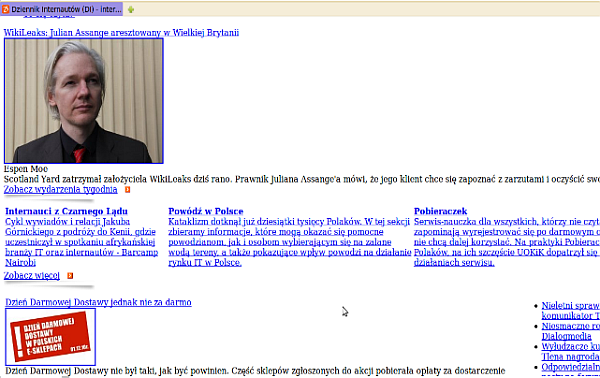
Każdy element, jaki widzą Państwo na stronie, charakteryzuje się pewnymi atrybutami. Między innymi są to wysokość, szerokość, marginesy, tło, kolor tekstu, obramowanie, pozycja, ułożenie względem innych elementów oraz informacja, czy dany obiekt w ogóle ma się wyświetlić. Jeżeli chcielibyśmy zrobić duży zielony kwadrat w HTML z czerwonym obramowaniem, to powinniśmy to napisać mniej i więcej tak:
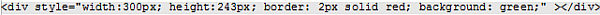
O ile wprawne oko szybko się rozczyta w tym, co przedstawia powyższa linia, o tyle osoba niedoświadczona po prostu zrobi wielkie oczy i machnie ręką, niczego nie rozumiejąc. Jeżeli umieścimy więcej takich elementów, to otrzymamy tego typu „spaghetti”:

Ktoś może zadać w tym momencie pytanie: „No to jak mam nie stosować CSS?”. Odpowiedź brzmi: „Stosuj, ale rób to z głową!”. W powyższym kawałku kodu mamy zawarte dwie informacje o naszym dokumencie. Jego strukturę, na którą składa się kontener DIV, akapit P oraz link A, oraz jego wygląd, który definiuje kod CSS. Tutaj rodzi się najważniejsze pytanie:
Jak w spaghetti rozróżnić wszystkie składniki?
Odpowiedź jest bardzo prosta. Skoro składniki (odpowiedzialne za wygląd i smak, jak CSS dla stron WWW) zostały wymieszane z makaronem (który jest podstawą dania, jak HTML w przypadku witryn), to teraz należy je oddzielić. Nasz fragment kodu HTML, bez części CSS opisującej jego wygląd, wygląda tak:

Część odpowiedzialna za wygląd (CSS) wygląda tak:

Zajmijmy się teraz kodem CSS. Jako że nie chcemy go w kodzie HTML, musimy zmienić troszkę jego zapis. Nie możemy używać atrybutu style z HTML, więc użyjemy zapisu z CSS:

Jako że na każde pole przypada jakaś właściwość, zapiszmy je jedna pod drugą dla lepszej czytelności:
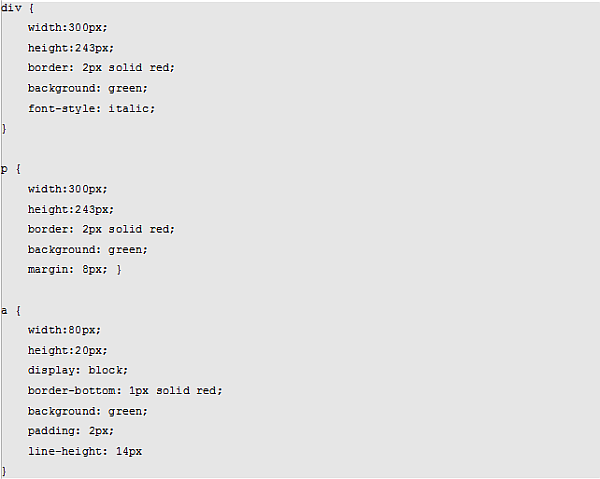
Tak przygotowany kod możemy spokojnie osadzić jako kod CSS na naszej witrynie bądź też zamieścić go w osobnym pliku. Jednak zawsze starajmy się go oddzielić od kodu HTML. Powód takiego postępowania jest bardzo prosty: raz przygotowany w ten sposób kod łatwo jest modyfikować.
Jeśli będziecie pisać kod tak, jak pokazane jest to na ilustracji pierwszej, zaręczam Wam, po dłuższym czasie sami będziecie spędzać znacznie więcej czasu, dochodząc, co i jak w nim zrobiliście.
Żeby załatwić cokolwiek w urzędzie, musimy wypełnić taką ilość papieru, że można by nim ogrzać dom całą zimę. Zdają sobie z tego sprawę szczególnie przedsiębiorcy. W sieci nie jest lepiej. Jeżeli otworzymy przeciętną stronę internetową, przywita nas spora liczba formularzy, przycisków itp.
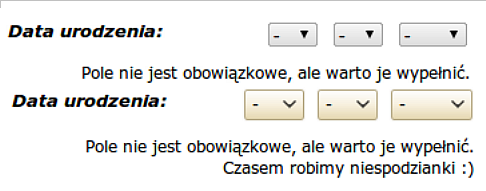
Jak napisałem, CSS opisuje wygląd elementów na stronie WWW. Niestety formularze są jednym z wyjątków od tej reguły. Każdy producent przeglądarek przygotowuje formularze na swój własny sposób. Głównie dlatego, że specyfikacja HTML nie mówi dużo na temat ich wyglądu. Pomija takie szczegóły, jak zaokrąglone rogi, wielkość i kształt dzióbka przy polu rozwijanym, kolor tła itp. Z tego względu prawie niemożliwe jest uzyskanie jednolitego wyglądu formularzy we wszystkich przeglądarkach, bez użycia zaawansowanego kodu JavaScript.
Jak sobie z tym radzić? Nie ma za bardzo jak. Po prostu nawet nie próbujcie definiować stylów dla pól formularza. Zostawcie je takimi, jakie są.
Nie tylko ludzie wyznają ten pogląd. Wygląda na to że przeglądarek też on dotyczy. Każdy element na stronie zawsze ma jakieś domyślne właściwości CSS, które go na starcie opisują. Dla przykładu, linki są wyświetlane na niebiesko. Nagłówki zawsze mają ustawioną większą czcionkę. Pola formularzy mają swoją wysokość, szerokość i wewnętrzny margines. Lista jest długa. Prowadzi to do tego, że nasza strona WWW nie ma jednolitego wyglądu we wszystkich przeglądarkach.
W sieci, na forach dyskusyjnych można znaleźć liczne porady typu:
„Zawsze stosuj margin: 0; padding: 0; border: 0;”. Moja osobista rada brzmi: „Gdy ktoś zaproponuje Wam wspomniane rozwiązanie, oznacza to, że trzeba poszukać rady gdzieś indziej”. Dlaczego? Gdyż jest to najgorsze rozwiązanie z możliwych. Jedną z pierwszych rzeczy, która się po prostu posypie na Waszej stronie internetowej, to właśnie formularze.
Znacznie lepszym rozwiązaniem jest zresetowanie właściwości CSS tam, gdzie występują różnice pomiędzy przeglądarkami. Jest na to doskonały sposób w postaci kodu CSS resetującego style przeglądarki autorstwa Erica Mayera. Kod ten jest dostępny pod adresem http://meyerweb.com/eric/tools/css/reset/. Innym rozwiązaniem jest kod Yui Reset CSS, który znajdziemy na Yahoo: http://developer.yahoo.com/yui/reset/. Wszystko, co należy zrobić, to dołączyć ten kod do naszej witryny.
W artykule „PHP a bezpieczeństwo” pisałem, że dobrego programistę poznaje się po tym, jak sobie radzi z błędami. Nie ma programistów takich, co błędów nie popełniają. Jest to reguła dla małych, średnich i dużych firm. Nie inaczej jest w przypadku producentów przeglądarek, takich jak Opera Software, Google, Mozilla czy Microsoft. Szczególnie ta ostatnia firma dała się we znaki webmasterom na całym świecie przez ciągłe odchodzenie od standardów W3C. Niemniej jednak wersja 8, a szczególnie 9 tej przeglądarki odchodzi od tego trendu, starając się zachowywać standardy W3C, które przecież Microsoft współtworzy.
Jednak wcale to nie oznacza, że tylko z przeglądarką Microsoftu są jakieś problemy. Jest to jeden z mitów ciągle powtarzanych przez webmasterów. Każda przeglądarka ma swoje „kwiatki”. Czasami wynikają one z błędów programistów, czasami z samej specyfikacji, która nie opisuje każdego przypadku użycia danego standardu. Dla przykładu weźmy Operę, która według mojego skromnego zdania ma jeden z najlepszych silników do renderowania strony WWW. Wystarczy, że w tablicy json nie będzie podanych kluczy i elementy bez nich polecą na sam jej koniec. Każda inna przeglądarka umieści je na początku (wychodząc z założenia, że brak znaku w ułożeniu od najmniejszego do największego da wartość najmniejszą). Z kolei Internet Explorer 8 i starsze potrafią po prostu zgłosić błąd JavaScript, gdy w tej samej tablicy json znajdzie się przecinek za ostatnim parametrem. Ta drobna przypadłość kosztowała wielu webmasterów całe godziny poszukiwania przyczyny błędu.
Firefox, Chrome, Safari i inne przeglądarki również mają swoje „kwiatki”. Nikt nie jest tutaj wyjątkiem. Co gorsza, bardzo często nie ma sposobu na obejście jakiegoś problemu z przeglądarką lub wymaga on dużego nakładu pracy.
Tutaj radę mogę zaoferować tylko jedną. Unikajcie problematycznych elementów. Niektóre przypadłości da się obejść sztuczkami. Dla przykładu, w starym Internet Explorerze 6, w momencie gdy element miał opływanie tekstu z lewej strony (float: left;) i jednocześnie lewy margines (margin-left:), to ten lewy margines był dublowany. Zamiast np. 20 pikseli miał on ich 40. Wystarczyło jednak ustawić elementowi liniowy tryb wyświetlania (display: inline;) i wszystko wracało do normy. Przy skomplikowanych kombinacjach niektóre elementy strony stawały się czarne. Traciły wszelkie style. Tutaj należało bardzo często nadać właściwość zoom: 1. Rzecz o tyle dziwna, że wartość 1 oznacza pierwotny rozmiar. Więc w teorii nie powinno się nic stać. Niemniej jednak wyświetlanie elementów strony wracało do normy.
Wątpię, czy do teraz ktoś wyjaśnił, o co chodziło programiście z tym nieszczęsnym lewym marginesem. Nigdy też się nie dowiemy, czy właściwość ta (a raczej błąd) miała coś na celu, czy po prostu była niezamierzona. Niemniej jednak Tobie, drogi czytelniku, zostaje tylko unikanie sytuacji, gdy błędy w jakiejś przeglądarce występują, polowanie w sieci na rozwiązania tych problemów oraz wymyślanie własnych. Bardzo często też będziecie musieli wprowadzać alternatywne rozwiązania tylko dlatego, że jedna z przeglądarek nie będzie danej technologii czy jej fragmentu obsługiwać.
Zawsze pamiętajcie, że najkrótsza droga do rozwiązania problemu nie zawsze jest najszybsza. Jeżeli przełożycie czas nad staranność wykonania, może się okazać, że w przyszłości stracicie znacznie więcej czasu. Jeżeli poświęcicie swój czas, by sformatować jakiś element strony, który formatowany być nie powinien, bezpowrotnie ten czas zmarnujecie. Zawsze starajcie się też poznawać ograniczenia przeglądarek, z których Wasz odbiorca może korzystać - tak by każdy dostał to samo, w ten sam sposób.
Dariusz Półtorak
Artykuł może zawierać linki partnerów, umożliwiające rozwój serwisu i dostarczanie darmowych treści.
 |
 |
|
|
|
 |
 |
© 1998-2026 Dziennik Internautów Sp. z o.o.


